I’ve worked in Statistics, Data Science, and Machine Learning for 12 years and like most other Data Scientists I’ve been thinking about how LLMs impact my workflow and my career. The more my job becomes asking an AI to accomplish tasks, the more I worry about getting called in to see The Bobs. I’ve been struggling with how to leverage these tools, which are certainly increasing my capabilities and productivity, to produce more output while also verifying the result. And I think I’ve figured out a framework to think about it. Like a logical AND operation, Data Science is a multiplicative process; the output is only valid if all the input steps are also valid. I think this separates Data Science from other software-dependent tasks.
{kind=link}
In contrast, coding up a Web app, a game, a GUI, an API, or a web server are additive processes (like a logical OR). Certainly there is a minimum level of “right” inputs to a functional web app; the buttons have to do something for it to work. However, a button can look off in a personal finance app, but it still works. If your browser-based game is kind of ugly, it can still be played. If your database updates are inefficient they can still do the writes. But Statistical Inference is different; if any join, filter, aggregation, or selection is off then the resulting inference is not useful. LLMs can generate code that runs, code that I can’t write on my own to fit Deep Learning, XGboost, PyMC, whatever other favorite predictive model is. The AI generated script will run. It will pass the tests, validate that all the input data files exist, and type check every input. But is it using the right observational unit in all of the joins? Did it silently drop a rare segment of your customer base that will cause poor results once the model is deployed? Did it align the observation and evaluation windows across all data sources? This level of knowledge is hard for humans to gather because it usually isn’t written down; there is no file to pull into the context or SKILL.md that outlines the rules your Data Engineering team uses to maintain a source table. To find mistakes at this level it usually takes digging into your data transformations and perturbing model inputs to verify model outputs.
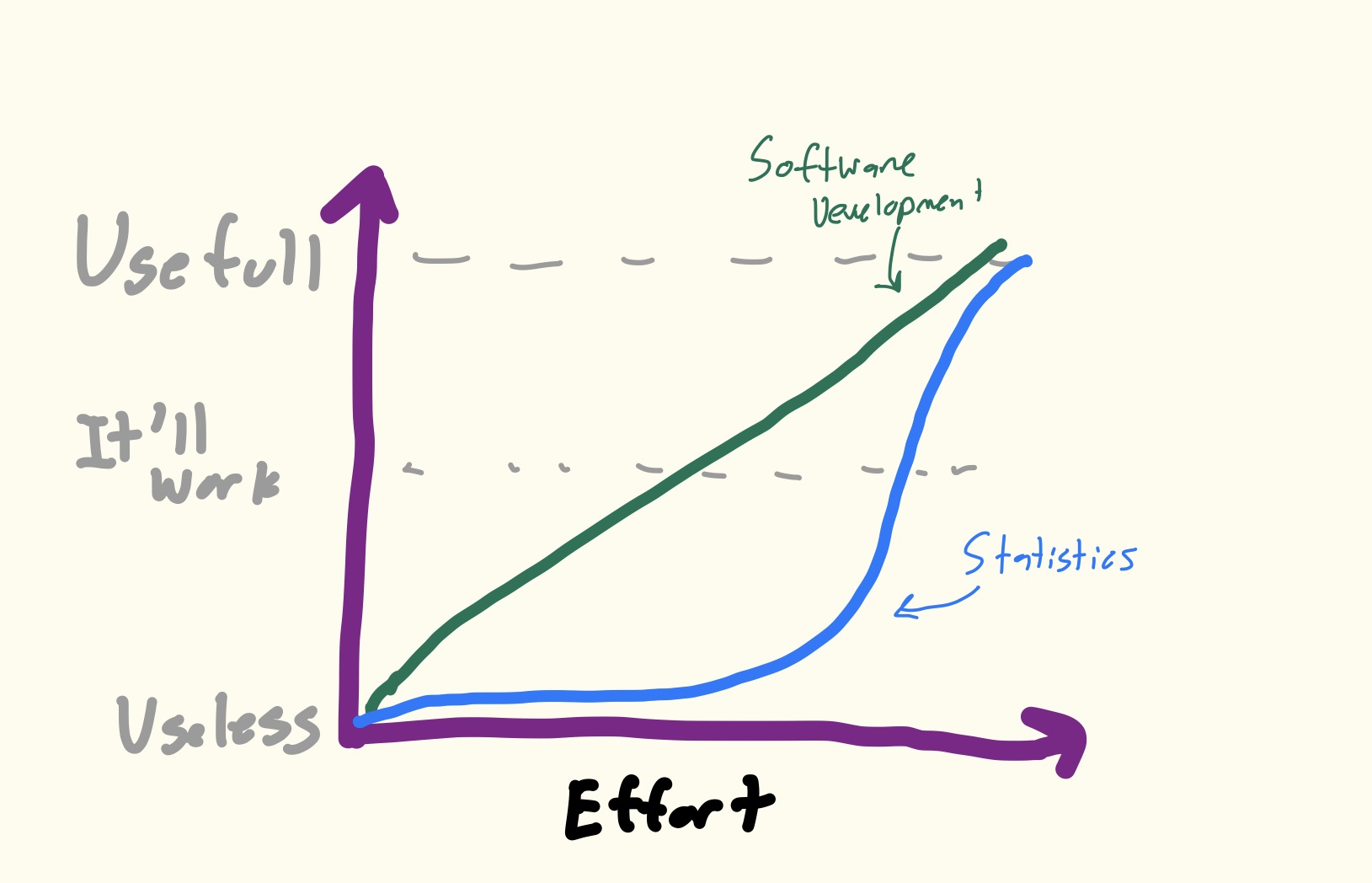
Now that I’ve enraged all the Software Engineers that are reading this I will take a moment to say none of this changes how vulnerable Data Science is to future model improvements and none of this is to say writing software, even with the help of GenAI, isn’t difficult and doesn’t require its own “learned taste” of where things will fail. The robots are coming for my job too, I promise. Instead, my point is that generating a usable piece of software is generally linear in terms of how much effort you need to put into a prompt or app to get a working version of what you are building. Data Science is more sigmoid; an 80% correct data pipeline gives you precisely 0 correct insights to leverage if that 20% introduces a bias into your outputs. Ok, maybe not totally useless but mostly useless. And I’m also sure I’m not the first person to have this insight, and I’m definitely not sure this is even correct. But it’s my hypothesis and I’m sticking to it.
So what can we, as good data stewards, do about it? I think there are two options:
- Write complete plans with all the little concerns and worries ahead of time
- Verify your data output with code
Point One is simple; creating a comprehensive outline, providing proper documentation, and pointing out potential pitfalls and areas of concern in your prompt to the coding agent will help with a lot of this. But I would like to focus more on Point Two. Unit Tests are like any process; just because you can measure (test) something doesn’t mean it’s what you should be focused on. Your script will run. Your helper functions will pass unit tests. But you need to verify what is important; Do I have all my observations moving from one step to another? Is my dataframe unique at the observation level? Do I have any nonsensical values? My 2nd least favorite LLM quirk is using print statements to validate data transformations. These don’t tell you if this number isn’t what it should be, it just shows you a number! And as AI keeps improving at accomplishing a wider range of tasks you are going to be juggling more active scripts at a time. Which means that you aren’t going to read code chunk by code chunk to verify the number printed in this section matches the number from the previous section (My least favorite quirk is all the defensive programming checks; if a file path doesn’t exist the read_csv statement will fail and tell me what line broke, what does telling me one line earlier going to help with?).
The {assertr} R Package comes to mind on tools we can use to do this. I’ve seen improvements in the reliability of my generated code by building an internal library that will perform these checks on my data. But the key insight to me is that these checks have to break your script if they fail; verifying print statements isn’t enough. Because if they silently fail your output is broken anyway, you may as well find out early.
That’s all I’ve got; make the LLM write tests that check the underlying data, not check the code. And sure, it could be any week that Opus-4.8 makes this distinction moot. But while we still have a job doing what we enjoy then maybe this framework will help you design your own safeguards and checks.
Humanity Oath: I solemnly swear that I did not use AI to write the words in this piece.
As a Data Scientist I’ve been thinking about how we can generate reliable Statistical Inference while allowing LLMs to actually write the code for us. I think what I’ve settled on is that you need to understand that Data Science is a multiplicative process, not additive.
Software Development (building apps and GUIs) is more linear; individual parts can look “off” or not work exactly right but your app can still work; it’ll be usable.
In contrast in order for your Model to be valid all of the underlying data manipulation has to be valid. Statistics has many thresholds where you get wrong results and then you cross over into right. Software development has more room in between useless and useful.
What can we do about it? I think you should use the LLMs to test your data, not your code. Print statements aren’t enough, you need to break your pipeline if your data is off.
Maybe this isn’t revolutionary, but thinking about it this way has helped me write more robust code at my job. You can read more about my thought process in my blog post: https://statmills.com/2025-05-03-datascience_llms/